Spark Streaming Tutorial
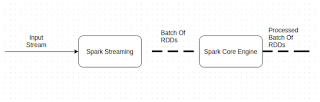
Spark has evolved a lot as a distributed computing framework. In the beginning, it was only intended to be used for in-memory batch processing. As part of Spark 0.7, it started to provide support for spark streaming. Spark streaming opened door for new set of applications that can be built using spark. Streaming systems are required for applications when you want to keep processing data as it arrives in the system. For example if you want to calculate distance covered by a person from it source using stream of GPS Signals.Batch processing systems are not suitable for such problems because they have very high latency, which means the result calculated will be received after considerable amount of delay. Let us understand some of the basic concepts of spark streaming, then we will run through some code for spark streaming as part of this post. DStream: Dstream is the core concept of Spark streaming which makes spa...