Spark Streaming Tutorial
Spark has evolved a lot as a distributed computing framework. In the beginning, it was only intended to be used for in-memory batch processing. As part of Spark 0.7, it started to provide support for spark streaming. Spark streaming opened door for new set of applications that can be built using spark.
Streaming systems are required for applications when you want to keep processing data as it arrives in the system. For example if you want to calculate distance covered by a person from it source using stream of GPS Signals.Batch processing systems are not suitable for such problems because they have very high latency, which means the result calculated will be received after considerable amount of delay.
Let us understand some of the basic concepts of spark streaming, then we will run through some code for spark streaming as part of this post.
DStream: Dstream is the core concept of Spark streaming which makes spark streaming possible. Dstream is stream of RDDs. In simple words words we can say, it is a micro batch of RDDs which will be processed by spark. Following Diagram will make it more clear.
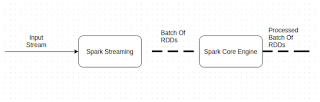
InputDStream: inputDStream is raw input rdd which is received from source. once received , we will do some processing on it and convert it into another DStream for further processing. We need to implement InputDstream for whichever source we want to connect with. For this example we need socket text stream. Spark provides an implementation for that. so we dont need to worry about this as of now.
Now lets get into some code. Before we start using spark streaming context we need to import some classes. following are the set of statements.
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
Now once we have imported these classes we can create a SparkConf object and using that we can create StreamingContext object. Remember, we used to use SparkContext. StreamingContext is used to build streaming applications.
// Create the spark streaming context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("Streaming word count")
val ssc = new StreamingContext(sparkConf, Seconds(1))
Now once we have streaming context ready, we can do any kind of processing on dstreams. let us try word count on the stream of input text
Before that let us create a inputDstream by mentioning source and some basic details
val dstreams = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK_SER)
Now let us write our word count code.
val words = lines.flatMap(x => x.split(" "))
val wc = words.map(x => (x, 1)).reduceByKey(_ + _)
wc.print()
after this we just need to start the whole streaming flow using following statement
ssc.start()
ssc.awaitTermination()
Now spark will start listening to localhost at 9999 port for input. you can send text input to that port by using following command
nc -lk 9999
after hitting this command in your linux shell. just type some text that you want to send as input and hit enter. you will see some activity and word count getting printed on the window where your spark program is running. Here are some images for your reference


Thank you for reading this post. please feel free to post your comments.
You can access the code for this at github
Streaming systems are required for applications when you want to keep processing data as it arrives in the system. For example if you want to calculate distance covered by a person from it source using stream of GPS Signals.Batch processing systems are not suitable for such problems because they have very high latency, which means the result calculated will be received after considerable amount of delay.
Let us understand some of the basic concepts of spark streaming, then we will run through some code for spark streaming as part of this post.
DStream: Dstream is the core concept of Spark streaming which makes spark streaming possible. Dstream is stream of RDDs. In simple words words we can say, it is a micro batch of RDDs which will be processed by spark. Following Diagram will make it more clear.

InputDStream: inputDStream is raw input rdd which is received from source. once received , we will do some processing on it and convert it into another DStream for further processing. We need to implement InputDstream for whichever source we want to connect with. For this example we need socket text stream. Spark provides an implementation for that. so we dont need to worry about this as of now.
Now lets get into some code. Before we start using spark streaming context we need to import some classes. following are the set of statements.
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
Now once we have imported these classes we can create a SparkConf object and using that we can create StreamingContext object. Remember, we used to use SparkContext. StreamingContext is used to build streaming applications.
// Create the spark streaming context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("Streaming word count")
val ssc = new StreamingContext(sparkConf, Seconds(1))
Now once we have streaming context ready, we can do any kind of processing on dstreams. let us try word count on the stream of input text
Before that let us create a inputDstream by mentioning source and some basic details
val dstreams = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK_SER)
Now let us write our word count code.
val words = lines.flatMap(x => x.split(" "))
val wc = words.map(x => (x, 1)).reduceByKey(_ + _)
wc.print()
after this we just need to start the whole streaming flow using following statement
ssc.start()
ssc.awaitTermination()
Now spark will start listening to localhost at 9999 port for input. you can send text input to that port by using following command
nc -lk 9999
after hitting this command in your linux shell. just type some text that you want to send as input and hit enter. you will see some activity and word count getting printed on the window where your spark program is running. Here are some images for your reference


Thank you for reading this post. please feel free to post your comments.
You can access the code for this at github

Comments
Post a Comment